Airin: Machine Learning Models
AI + Machine Learning
Developing a recommendation system for AI software that augments IT Subject Matter Experts and helps them ask better questions.
Airin is a well-funded startup creating an AI expert system platform for enterprise IT customers. It augments Subject Matter Experts in developing and sharing problem statements, identifying the right questions for a given problem, and understanding the context around decision making. Although Airin has their own development team, they engaged Objective to help them develop machine learning models.
The Airin website.
The Problem
Given a customer's arbitrary problem statement, predict the most relevant set of questions
When a user has a problem statement such as, “I’d like to move my on-premise server infrastructure to the cloud”, we wanted to see the platform recommend question sets related to that individual’s objectives. Our goal was to come up with a proof of concept demonstrating that this is actually feasible and that a natural language processing approach to the problem can produce results that are better than a simple full text search approach.
Our Approach
01 Exploratory Data AnalysisWe analyzed 15,826 content items and developed a baseline for comparing results
Understanding the relationships between question sets
Before data can be used in machine learning, the data has to be explored to fully understand the nuances of its structure, its quality, and the relationships that might be represented within. Airin provided us with 126 question sets containing 15,826 content items. We analyzed these to understand the distribution of questions, statements, follow-up questions, and section headers.
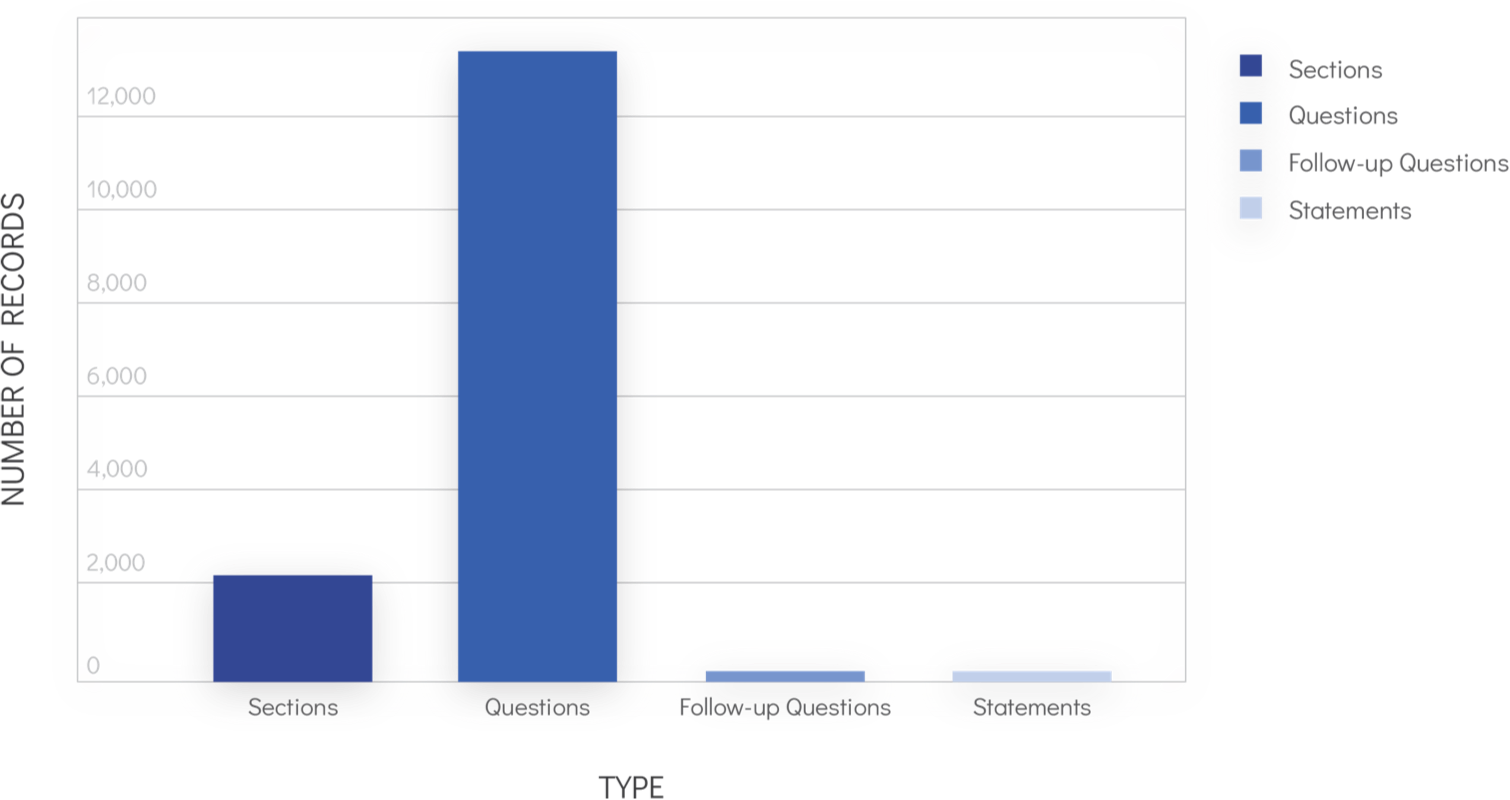
Distribution of content types.
Developing a baseline
Before training a machine learning model on the data, we needed to know what the baseline results were. There are two common approaches to setting a baseline in a classification problem:
- Choose the most common class and use its ratio in the data
- Use the statistical probability of guessing correctly by chance
Both of these approaches yielded a very low baseline (3.7% and 0.8% accuracy). There was a lot of room to improve beyond either baseline!
02 Iterative ExperimentationWe developed and trained a custom machine learning model
Transforming all text to numerical representation
Building a classifier involving language data required us to convert the words into numbers. This process can be explained in four steps.
- Convert each word to a token
- Choose a token representation—for our Proof of Concept we used GloVe
- Convert tokens to numbers
- Combine tokens in a given text by averaging each element across the vectors
Training a model, evaluating performance, recleaning, and iterating
In order for data to be useful to a model that can be trusted, the data often needs to be manipulated and cleaned. We used T-SNE, Altair, and KMeans clustering to group, visualize, and find problems with the data. We then ran the data through various machine learning algorithms such as logistic regression, decision trees, and the random forest classifier to determine if the approach would improve the accuracy of our model. Several cycles of this step improved the ability of the models to produce reliable predictions in the desired 90% range.
First Iteration
11%
Accuracy
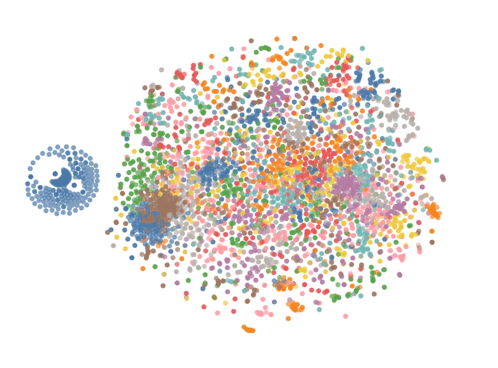
Issues
- Many questions were duplicated
Solution
- Remove duplicates
Second Iteration
27%
Accuracy
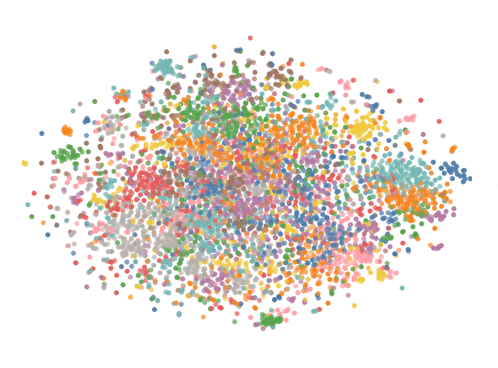
Issues
- Generic questions
Solution
- Combine model title with content items for context
Third Iteration
93%
Accuracy
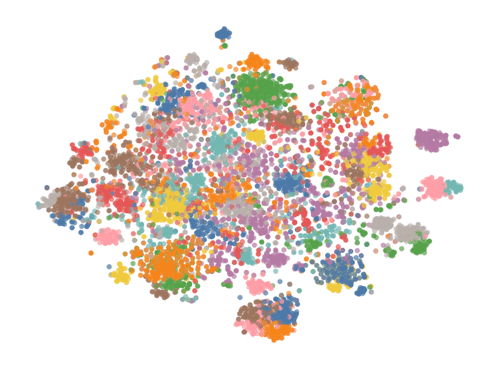
Caveats
- Duplicate models were left out
- Model titles have a strong effect
- No problem statements to verify against
The Result
We prototyped a system that allowed the client to experiment with our machine learning model
In order to showcase our results to the client in a way that is usable, we created a prototype system using a four step process.
- Create a new Python class to wrap the transformation and training
- Train and save the ML model
- Create a basic web service using Flask (a minimalist Python framework)
- Make it portable with Docker
This allowed the client to experiment with our machine learning models to truly learn what they are capable of doing and to see how they can apply our models in their product.
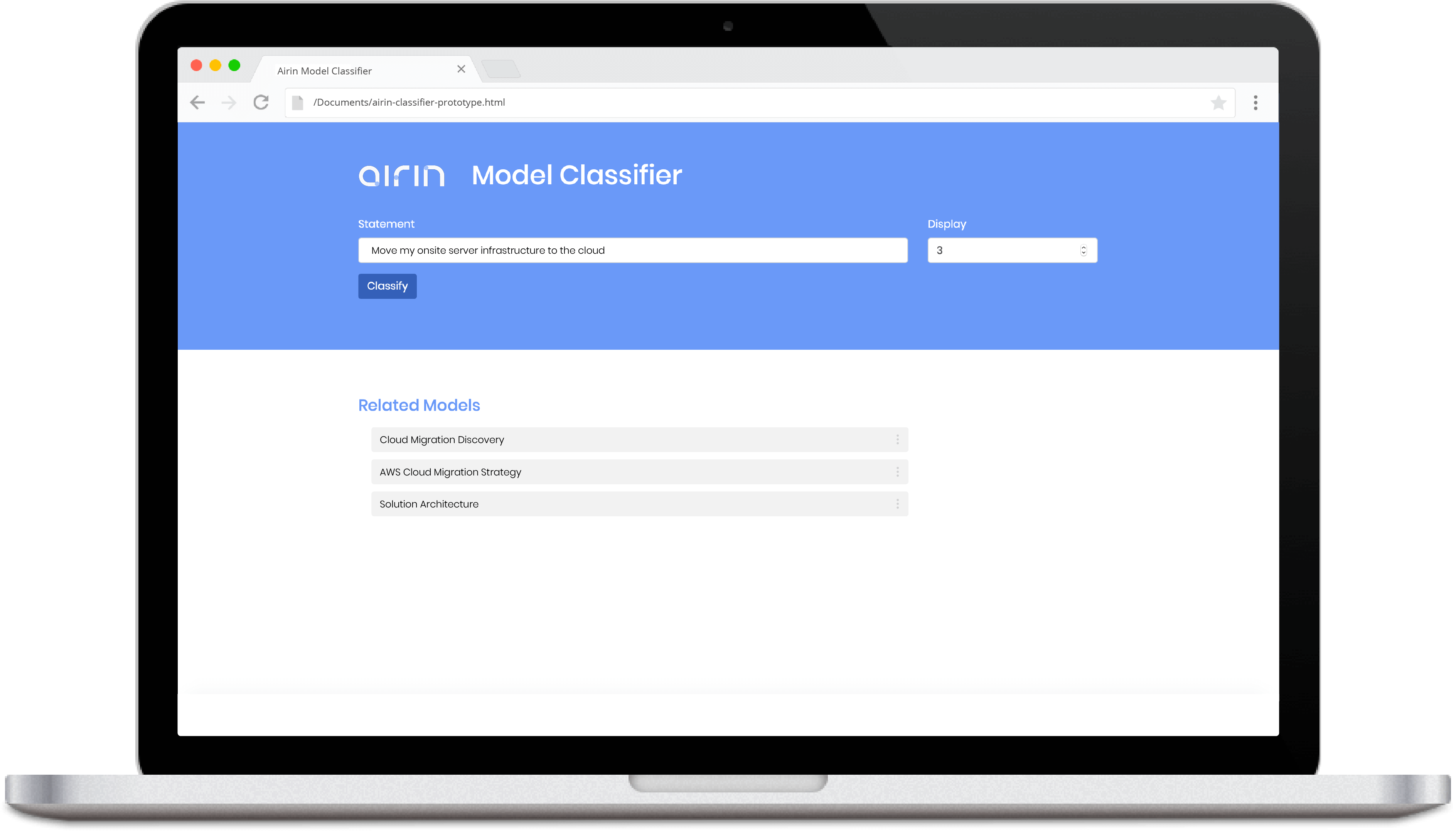
A screenshot of the prototype.
We are so glad we engaged Objective to help us explore and develop new machine learning models! Objective listened carefully to our goals and worked closely with our team to produce a valuable and usable outcome. Their expertise & AI models have really helped us shape our product. We couldn't be happier with the results.
We're excited to work on your project next
Wondering what this means for you? Our work in natural language processing and machine learning makes us a perfect fit to develop your chatbot, customer service tool, Slack integration, or product/customer review analysis tool. Need predictive, risk, or churn analysis? We can do that, too.


